皆さん、自動運転ってすごいですよね。
自動運転は段階として、5段階あり、日本では、2020年からレベル3 が市場に流通し始めるそうです。
※レベル3は限定的な条件(高速道路など)でのみ自動運転、緊急時は人間が操作。
レベル5の自動運転は、家から寝ていても目的地に着く理想的な自動運転です。
そして、今回の記事のテーマ DeepRacerが現実の⾃動運転とどう関係していくのかといいますと、実際に北米でGoogle の waymo という自動運転サービスがあり、公道で実験をしています。
どちらの自動運転も周りの環境を認知するためのカメラがついており、カメラからの画像情報を取得し、そこから周りの環境について解釈することで、自機の今の状況を判断する根拠としています。
安全な自動運転が実現するには、非常に重要で不可欠なプロセスです。
もし、カメラから入る情報が攻撃者によってマスクされ、赤信号を青信号として認識してしまうなどの攻撃が行われれば、それはそれは大変なことになってしまいますね。
セキュリティって大事なんですね(セキュリティ企業ブログとしてのノルマを雑に達成)
そんなわけで、今回はDeepRacerについてのお話です。
おまけのAWS参戦記(地獄の実機編)までお読みいただければ人間(筆者)は嬉しいです。
AWS DeepRacer とは
AMAZONが催しているAIレーサー育成ゲームです。
AWSと頭につくので、察しの良い方はおわかりだと思いますが、いちいちお金がかかります。
今回は、2019年6月12日-15日に開催されたAWS Summit TOKYO 2019 への参加に向けてAIレーサーを教育していったのですが、
1時間教育するのに、大体 7ドル ぐらいかかります。
周りに経験者のいない強化学習が初めての方が1周するようなレーサーを育成するとなると、2万円は欲しいかもしれないです。
エンジンを始動しましょう
モデルって?
教育されるAIの個体のことです。

AWS Summit TOKYO に向けてなにをしたか
1トレーニングにつき60分~180分ぐらいかけてAIの育成方針を模索していました。
下記に派生図を示します。
v1-v5┬v6┬v7-v8┬v11
│ │ └v12┬v13-v18-v19-v20-v21-v22┬v23-v24-v25-v26-v27
│ └v9-v10 │ └v28
│ ├v14
│ └v15
└v17くっそ迷走してますが、v18 の頃に方針の腹を決めています。
v17 までは、中心寄りかつ右寄りで走って欲しかったので、それを完璧にしようとしていましたが、一向に改善されなかったためやめました。
v17の以下の図を示します。

このグラフは報酬関数(reward_function)により、return された [reward]の値の1分(840-960Step程度)毎の合計値です。
上下をうろうろしていますが、なかなか右肩に上がりません。
困りましたね。
強化学習ではこの報酬関数というものが使われます。
※報酬関数とは、自分が考えた最強のアルゴリズムとそれに応じた[reward]の値を実装し、より理想的な動きを機械にしてもらうための関数です。
ですので、私たち人間はアルゴリズムを考え、(DeepRacerではpythonで)実装し、コードのValideteを無事に通すまでが仕事です。
あとは、実装した報酬関数の処理に沿って、機械ができるだけ報酬の高くなる解を求めて右往左往しているグラフを眺めてウットリして過ごします。
色々模索した結果、トレーニング後の検証(evaluation)で5回100%を取る天才レーサーが誕生しました。
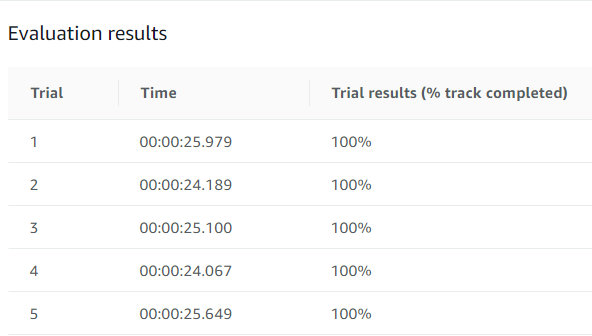
かかった時間(人間が手を動かしたりウットリしていた時間)
35時間
どんな実装をしたのか
import math
# main
def reward_function(params):
# パラメータ取得
all_wheels_on_track = params['all_wheels_on_track']
x = params['x']
y = params['y']
distance_from_center = params['distance_from_center']
is_left_of_center = params['is_left_of_center']
heading = params['heading']
progress = params['progress']
steps = params['steps']
speed = params['speed']
steering_angle = params['steering_angle']
track_width = params['track_width']
waypoints = params['waypoints']
closest_waypoints = params['closest_waypoints']
# 定数の設定
MIN_REWARD = 1e-3
SPEED_THRESHOLD1 = 2.7
SPEED_THRESHOLD2 = 4.0
SPEED_THRESHOLD3 = 5.4
SPEED_THRESHOLD4 = 7.0
DIRECTION_THRESHOLD1 = 4.0
DIRECTION_THRESHOLD2 = 3.0
ABS_STEERING_THRESHOLD = 7
marker_1 = 0.1 * track_width
marker_2 = 0.2 * track_width
marker_3 = 0.5 * track_width
# 変数の初期化
reward = 0.3
steering_reward = 1.0
speed_reward = 1.0
progress_per_steps_reward = 0
progress_reward = 1.0
### 各報酬付与関数の実装 ###
# 車両がトラックラインの外側に出たら終了
if not all_wheels_on_track:
reward = MIN_REWARD
return reward
# 直線の第一区間および第十区間
# スタートおよびゴール付近は直線なので、センターラインに近く、速度が速ければ速いほど報酬
# headingの向きがX軸に平行なら加点
# センターラインに近ければ得点を増やさせる
if 2.5 <= x <= 7.0 and y <= -1.5:
if distance_from_center <= marker_1:
reward = 1.3
elif distance_from_center <= marker_2:
reward = 1.0
elif distance_from_center <= marker_3:
reward = 0.05
# スタート付近は直線なので、センターラインに近く、速度が速ければ速いほど報酬
if speed < SPEED_THRESHOLD3:
speed_reward = 0.05
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 1.1
elif SPEED_THRESHOLD4 < speed:
speed_reward = 1.5
# headingの向きがX軸に平行で右向きなら加点
if -4 < heading < 4:
steering_reward = 1.3
# 緩やかな左カーブの第二区間
# 通れたらプログレスにちょっとだけ報酬
# スピードで報酬
if x > 7.0 and y < -1.0:
# 常に生存報酬
reward = 1.3
# 緩やかなカーブなので速度が早ければ報酬、遅すぎたらペナルティ
if speed < SPEED_THRESHOLD3:
speed_reward = 0.05
elif speed < SPEED_THRESHOLD4:
speed_reward = 1.1
elif SPEED_THRESHOLD4 <= speed:
speed_reward = 1.3
# タイヤの方向が左を向いていたら報酬
if 0 <= steering_angle:
steering_reward = 1.3
else:
steering_reward = 0.2
progress_reward = 1.05
# ほぼ直線の第三区間
# 報酬は速度とセンターラインへの近さ
if 7 <= x and -1.0 <= y <= 1.2:
# カーブを安定させるために、センターラインに近ければ報酬増加
if distance_from_center <= marker_1:
reward = 1.3
elif distance_from_center <= marker_2:
reward = 0.8
elif distance_from_center <= marker_3:
reward = 0.1
# 速度報酬
if speed < SPEED_THRESHOLD3:
speed_reward = 0.5
elif speed < SPEED_THRESHOLD4:
speed_reward = 1.1
elif SPEED_THRESHOLD4 <= speed:
speed_reward = 1.3
# 急な左カーブの第四区間
# 速すぎたらペナルティ
# タイヤの方向が左を向いていたら報酬
# progressに報酬増
if 6 <= x and 1.2 < y:
# 常に生存報酬
reward = 1.3
if speed < SPEED_THRESHOLD1:
speed_reward = 0.9
elif speed < SPEED_THRESHOLD2:
speed_reward = 1.3
elif speed < SPEED_THRESHOLD3:
speed_reward = 1.3
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 0.1
# タイヤの方向が左を向いていたら報酬
if 0 <= steering_angle:
steering_reward = 1.3
else:
steering_reward = 0.2
# progressに報酬増
progress_reward = 1.1
# 急激な右カーブの第五区間
if 6 <= x <= 7 and -1.5 < y <= 1.2:
# 常に生存報酬
reward = 1.4
# 速すぎたらペナルティ
if speed < SPEED_THRESHOLD1:
speed_reward = 1.2
elif speed < SPEED_THRESHOLD2:
speed_reward = 1.1
elif speed < SPEED_THRESHOLD3:
speed_reward = 0.1
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 0.1
# タイヤの方向が右を向いていたら報酬
if steering_angle <= 0:
steering_reward = 1.0
else:
steering_reward = 0.2
# progressに報酬増
progress_reward = 1.2
# 5と6の間のフリーな区間
if 5 < x < 6 and -1.5 <= y:
# 常に生存報酬
reward = 1.4
if speed < SPEED_THRESHOLD1:
speed_reward = 0.1
elif speed < SPEED_THRESHOLD2:
speed_reward = 1.3
elif speed < SPEED_THRESHOLD3:
speed_reward = 1.1
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 0.1
# progressに報酬増
progress_reward = 1.1
# カーブを安定させるために、センターラインに近ければ報酬増加
if distance_from_center <= marker_1:
reward = 1.3
elif distance_from_center <= marker_2:
reward = 1.0
elif distance_from_center <= marker_3:
reward = 0.05
# ぐねぐねの第六区間
# 速度報酬
# headingの向きをなるべく平行にしたら報酬増
if 3 <= x <= 5 and -1 <= y:
# 常に生存報酬
reward = 1.4
# ぐねぐねしているが早ければ報酬、遅すぎたらペナルティ
if speed < SPEED_THRESHOLD2:
speed_reward = 0.5
elif SPEED_THRESHOLD2 < speed:
speed_reward = 1.1
# ジグザグ抑制
if steering_angle < ABS_STEERING_THRESHOLD:
steering_reward = 1.2
# progressに報酬増
progress_reward = 1.1
# ぐねぐね明け左カーブの第七区間
if x < 3 and -1.2 <= y:
# 常に生存報酬
reward = 1.3
# 緩やかなカーブなので速度が早ければ報酬、遅すぎたらペナルティ
reward = 1.3
if speed <= SPEED_THRESHOLD1:
speed_reward = 0.1
elif speed < SPEED_THRESHOLD2:
speed_reward = 0.9
elif speed < SPEED_THRESHOLD3:
speed_reward = 1.1
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 0.1
# タイヤの方向が左を向いていたら報酬
if 0 <= steering_angle:
steering_reward = 1.2
else:
steering_reward = 0.1
progress_reward = 1.05
# カーブ前若干ストレートの第八区間
if x <= 2.5 and -1.7 <= y < -1.2:
# カーブを安定させるために、センターラインに近ければ報酬増加
if distance_from_center <= marker_1:
reward = 1.3
elif distance_from_center <= marker_2:
reward = 1.1
elif distance_from_center <= marker_3:
reward = 0.05
# 速度が速ければ速いほど報酬だが、速すぎたらペナルティ
if speed <= SPEED_THRESHOLD1:
speed_reward = 0.1
elif speed < SPEED_THRESHOLD2:
speed_reward = 0.9
elif speed < SPEED_THRESHOLD3:
speed_reward = 1.1
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 0.1
# headingの向きがY軸に平行で下向きなら加点
if -95 < heading < -85:
steering_reward = 1.2
# 最後の左カーブの第九区間
# 周回を安定させるために、センターラインに近いと報酬増加
# 速度が速ければ速いほど報酬だが、速すぎたらペナルティ
if x <= 2.5 and y < -1.7:
# 周回を安定させるために、センターラインに近いと報酬増加
if distance_from_center <= marker_1:
reward = 1.3
elif distance_from_center <= marker_2:
reward = 1.1
elif distance_from_center <= marker_3:
reward = 0.05
# 速度が速ければ速いほど報酬だが、速すぎたらペナルティ
if speed <= SPEED_THRESHOLD1:
speed_reward = 0.1
elif speed < SPEED_THRESHOLD2:
speed_reward = 0.1
elif speed < SPEED_THRESHOLD3:
speed_reward = 1.1
elif SPEED_THRESHOLD3 <= speed:
speed_reward = 1.2
# タイヤの方向が左を向いていたら報酬
if 0 <= steering_angle:
steering_reward = 1.2
else:
steering_reward = 0.2
progress_reward = 1.05
# すべてに共通して、進んでいるのでプラス
reward += progress * progress_reward / 200
reward += steering_reward
reward += speed_reward
# waypoint考慮して、角度が頭の向きとズレすぎていたらペナルティ
next_point = waypoints[closest_waypoints[1]]
prev_point = waypoints[closest_waypoints[0]]
track_direction = math.atan2(next_point[1] - prev_point[1], next_point[0] - prev_point[0])
track_direction = math.degrees(track_direction)
direction_diff = abs(track_direction - heading)
if direction_diff > DIRECTION_THRESHOLD2:
reward += 0.2
elif direction_diff <=DIRECTION_THRESHOLD2:
reward += 1.1
reward *= 0.85
return reward実装で気を付けたいこと
実際に実装して、DeepRacerの走行シミュレータをかけるとわかるのですが、
Validateをクリアしたコードは構文に問題がないことは保障されていますが、
本当に機能しているのか、についてはシミュレータのカメラからは一切判断できません。
そこでログを吐き出す処理を実装する必要があるんですね。(実装するだけではなく、CloudWatchでログを見るまでが必須)
検証で良い結果がでてるからと言ってサボってはいけません。
とても大事なことです。(22敗)
本当です。
ログを吐き出す実装はちゃーんとif文のtrue と false 側に実装しましょう。
if :
print("Nice Handling")
else :
print("Bad Handling")
これバグ?
時折、バグというより仕様(?)のような現象がみられます。
コースアウトした後、コース内に戻らずずっと木にぶつかったままの状態になる
- コースアウトしても戻ってリスタートしない状態を見かけた場合、しばらく観察して、本当に戻らなそうなら、泣く泣く[Stop Training] を押下しています。
一周すると、しばらく止まって、動き出すが、まっすぐ突き進んでコースアウトする。
- しばらく待ちましょう。時間と金が勿体ないですが、、、
チューニング結果
いい感じに仕上がってますね~
シミュレータを通して...
DeepRacerを初めた頃、
自分が実装したかわいいかわいいDeepRacerちゃんが、壁(コースアウト)にぶつかりながらも懸命に前へ前へ進んでいく様を眺めることができ、ウットリできて、本当にかわいいです。
しかし、ある程度AIがルール(一周することが大事、コースアウトはしてはいけない)などを覚えた中盤以降、成績が伸び悩むと腹が立ちます。
例えば、「この部分工夫したアルゴリズム実装したら早くなる」、「完走率が上がる」などと人間が期待して夜な夜な実装し、走らせて、検証すると、実装前よりも成績が悪化している といった現象も多くみられます。
AWS Summit TOKYO に行ってきました。


地獄の実機編
2019年6月12日、初めてのリアルレースができると胸を高鳴らせて意気揚々と望みました。 会場に到着し、いざDeepRacerのBoothへ そこに待ち受けていたのは、、、、コース「"re:invent2018"」

AWSサミットで行うリアルレースではお決まりのコースですね。
kumo Torakku にお金と時間費やしていたような 方はいませんよね?(煽り
ん?
あれ?!!!!!!!!!!!!!!!!!
はい、学習させるコース、間違えました。
今頃反省しても遅いので、エンジン全開です。(ブオォォォォォォオンン!!!!!!
走らせる予定だったモデル(シミュレータでKumo Torakkuの練習をしたもの)に
シミュレータにて"re:invent2018"を走らせてみると、軽々と完走していたので、
そこまで大きな問題ではなかったとして、レースに臨みました。
以下、箇条書きの感想です。
- シミュレータとは違い、任意の速さを手元のタブレットで都度調整して走行できて拍子抜けした。
- タブレットの速度調整のボタンが押しづらい(連打すると拡大する)
- 待ち時間が長い(実際に走らせることができるのは4分のみ
- レース出場者はモデルを共有していても大丈夫です。ですので、会社で最強のモデルを1つ作ってからみんなでレース会場に行き走らせれば上位を独占できます。
- 速度重視でいきましょう(コースアウト3回まで許容ルールのため)
- シミュレータと違い実機ではタイヤとコースの質感が加わることで、クセのあるAI走行に早変わりします。そのため、シミュレータで100%を5回出してようが問答無用でコースアウトし、記録が出ないなんてこともよくあります。(大金を使ってシミュレータを回す意味とは???
- また、コースアウト時の判定や、リスタート位置は係員によって若干異なります。人間ですからしょうがないですね。
- 会場は会社ぐるみの札束で一位を奪い合う戦争のようなバチバチの様相でした。へらへらしながら行くような場所ではなかったです(猛省
- レース場で実機のマシンは複数台あり、終わり直後は煙を吹くほどでしたが、ローテーションさせて きちんと熱を逃がしてから走行させています。また、シャフトが曲がるほどの厳しい走行をマシンに強いているため、リペアが大変そうでした。
かかった金額
27万円 ※3人同時に学習を行ったため。
遊んだ後のお片付け
https://aws.amazon.com/jp/blogs/news/aws-deepracer-delete-resources/
S3 バケットの削除と[Reset resources]をお忘れなく。
一番良いモデル や 派生していきたいモデル だけを残して他のモデルを削除してしまいましょう。
ここまで読んだ方へ
DeepRacerのリアル大会で1位を取るのは、かなりの労力とお金、時間が必要なので、
本当にラスベガスに行きたいのなら、チケットを買って普通の手段でラスベガスに行きましょう!